Back in March 2011, I wrote a web application to estimate how many Chinese words a person knows. The test works similar to a flashcard set: for each word presented, you mark whether you know the word (using your own judgment), optionally revealing the pinyin and English definition before deciding. A sample of 165 words is drawn from the top 36,000 in the Lancaster Corpus of Mandarin Chinese. At the end, the results are extrapolated across frequency bands to give an estimated vocabulary size. A Chinese character test was added later, with the same methodology, but at the character level rather than the word level. The app has been quietly running for 15 years now.
The app now has a new test – Vietnamese! It’s been something I’ve wanted to add since starting my Vietnamese studies last year, to get an estimate of my progress at various points. The test follows the same format as the Chinese ones – a sample of words drawn from a frequency list, marked known or unknown, with a vocabulary estimate at the end. Before the main test, there is a short pre-test with a few questions to gather some anonymous information about your current level of Vietnamese. This data will be used for future analysis, similar to the original research motivation behind the Chinese test. If you are a Vietnamese learner at any level, give it at try! The tests are all at https://www.zhtoolkit.com/apps/wordtest/.
For some personal reasons, I have a recent project to learn Vietnamese, not just basic words and phrases, but to become somewhat fluent. With all the years of studying Chinese, I had never gotten past an intermediate level. That level of fluency would be my goal for Vietnamese. It’s enough to read basic books and know about 70% of the text. And it’s enough to have basic conversations and be able to express myself, even if I need to substitute unknown words on occasion.
Jumping into a language completely cold is a great opportunity to take all that I have learned from Chinese, and see what applies more generally to language learning. What tools and strategies can advance my levels quickly, without getting sidetracked on ineffective methods?
First impressions
I have gone to Saigon twice, once a year ago, and again last month. The only studying I had done up to last month was a few Pimsleur lessons. I had learned to say “How are you” and was excited to use it. When I said it to my friend’s mother, it turns out I had used the wrong pronoun considering our age differences, and it was offensive. I also used standard Vietnamese and not the Saigon dialect, so it was the wrong syntax anyway. The result was just confusion on their part. It was discouraging, but it also woke me up to understand that it’s not going to be an easy language to learn.
Last year when I went, I stayed with my brother who lived in Saigon and spoke English. There was no need to know any Vietnamese, and I left the trip not having picked up anything. Then, a month ago, I went to Vietnam with a friend, and we stayed with her extended family. This was a completely different experience, and my lack of language skills became a clear problem. I needed to quickly pick up some useful phrases to get by. Since my friend was a native speaker, all I needed were a few survival phrases. It turns out this is all I needed:
bathroom
man/woman (to distinguish bathroom signs)
what is your name
it’s nice to meet you
thank you
hello
good morning/afternoon/evening/night
see you later
it’s delicious
I’m full
I’m tired
My stomach is bad (yes, you can have too much noodle soup)
excuse me/I’m sorry
pronouns!
Some other terms that I didn’t use but might have been useful for rudimentary conversation include:
yesterday/today/tomorrow
my job (IT or “computers”)
numbers 1-10
months
expressing time
to go/arrive/return
Unlike English and Chinese, it’s critical to use the correct pronoun, considering the person’s gender along with your relative ages. My impression so far is that using the wrong word to address someone is a serious offense that is going to cause some bad feelings. There are neutral pronouns to play it safe, and every formal lesson I have encountered so far — Pimsleur, textbooks, and flashcards — all use these neutral pronouns. If you relied solely on these, you would be missing a lot of important practical usage.
Similar to Chinese, Vietnamese has tones. There are a few more than standard Mandarin, but at least I was prepared for it and knew to include it in my word learning. But Vietnamese has many vowels and vowel combinations, and those also have diacritical marks. I hadn’t learned to read these, and vowel diacritics and tone markers all meant the same for me. But  is a flat tone vowel, à is a tone, and Ẫ is a vowel with a tone.
A lot of Vietnamese is pronounced very different from how it’s spelled. Chinese (pinyin or other English representation) did have that too, like xin and qin and si. Vietnamese has more letters, and more variations. if you have ever ordered phở (beef broth soup), you already know that it is not pronounced like English “foe”. And many sounds are unfamiliar to English speakers, and it is taking some training to move my mouth in different ways. Correct speaking is essential, as it’s easy to be misunderstood with just a slight difference in tone or pronunciation accuracy. I will prove this out someday, but my hunch so far is that there are more one syllable words in Vietnamese than in Chinese. This means that there is a higher ambiguity with an incorrect word since there is less context to compensate for it. Apparently, “I want to buy a house” sounds similar to “I want to sit now” at the poor speaking level I am at so far! As a bonus, I need to focus on Saigon dialect, while most learning material is the Hanoi dialect.
The same goes for spelling, as the correct diacritics and tone marks are necessary for being understand. The built in input method in both Windows and Android is TELEX, which allows adding marks by inputting extra letters after the vowels. It isn’t too hard to pick up. Writing out words has helped me remember words better, since I need to pay attention to the exact spelling, versus casual reading in which it’s easy to gloss over the vowel marks.
Vietnamese uses the Latin alphabet (plus all the diacritics) instead of characters. But it is similar to Chinese in that words are all separated per syllable. Thus, some mental processing is required to parse out the actual words from these syllables. In my first attempt at reading a full text, I really had no idea what I was looking at. Without being able to pick out key words, reading any text isn’t something I can tackle at this point.
With all that in mind, how should I study?
Proposed strategies
I don’t know an easy hack for learning Chinese, or any language at higher levels. What worked for me was a lot of exposure, and spaced repetition in both reading and writing. I drew from available dictionaries, corpora, and word lists available for download, along with my own Chinese Word Extractor program to create word lists and flashcards from texts. Once I knew enough words, reading texts was possible, and that allowed for even more exposure. But my biggest accomplishment was being able to read Harry Potter in Chinese. In fact, I still haven’t read it in English.
Attempting the same for Vietnamese, I see how spoiled I was with Chinese. As of now, there are 807 Aniki flashcard shared decks for Chinese flashcards. In Vietnamese, there are 123, and many of those are for learning English from Vietnamese, or Chinese from Vietnamese. Chinese has Pleco software which is a great tool for dictionary lookups and etymology. Chinese has official word lists geared for the various levels of the HSK exams.
To get up to speed, I want to set up my pipeline of flashcards to rapidly achieve a base knowledge of core words. Flashcard lists with Vietnamese audio would be especially useful.
The Anikweb flashcards I started with are these:
Xefjord’s Complete Vietnamese (Southern): 201 words and phrases with audio. I went into Vietnamese completely cold, so having audio cards was helpful to start with. Skip the “Core Vietnamese Vocabulary” which is just 16 phrases with some weird ones like “Hello America.”
Vietnamese to English vocab and practice: 500 sentences and 1069 words. No audio, but the example sentences are pretty reasonable for a beginner level, helping with both common words and grammar
I created a fork of my Chinese Word Extractor program that works with Vietnamese. It is still in progress, but modifying the logic to handle Vietnamese instead of Chinese was only a few hours of effort. The greater work was updating the program for Python 3, and switching the GUI framework from WX to tkinter. For a free Vietnamese to English dictionary, I used VNEDICT from Paul Denisowski, who was actually the original creator of CEDICT.
Armed with a vocabulary extractor, I can now create my own word lists. So far, I have taken a list of parsed words from OpenSubtitles, combined it with VNEDICT English definitions, and made a flashcard set from the top 1000 most frequent words.
Eventually, I will make a Vietnamese version of my Word Test online program to track my word knowledge.
I will spend about an hour every day studying. Keeping in mind my rough starting date of March 3, 2025, I want to keep more notes on the timeline for major milestones. While the results are entirely personal, it will give me a rough idea of how long it would take to learn any language with little to no prior knowledge.
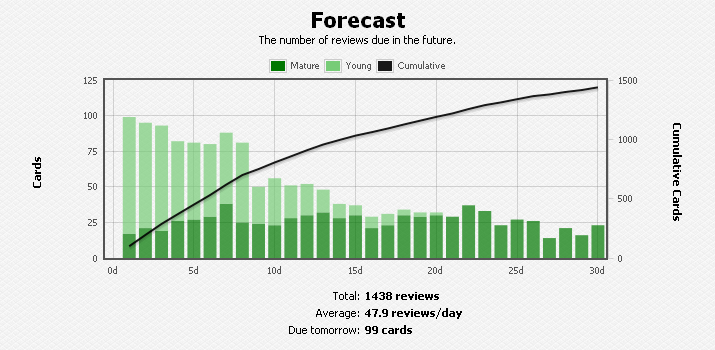
While I do enjoy studying Chinese words using Anki, I must admit it can feel like a chore much of the time. I tend to aggressively focus on challenging words, which often means that my queue for the day is filled up to the daily limit, and also that I’ve given myself a challenging workout. My usual habit at the beginning of a session is to check Anki’s forecast graph to check, even though I had a lot to study today, when my diligence will pay off.
Anki forecast at day 105
It is a real encouragement to see how great the future looks. While I have 99 cards to study today, all I have to do is study hard for about a week, and the number of cards due will be down by half. The graph continues to indicate reductions in the number of cards day by day, leveling off after two weeks to about 25 cards per day. I can imagine how awesome my study routine will be two weeks from now, when the spaced repetition algorithm will just require me to pull up Anki a few minutes a day of flashcards to in order to retain learned material.
The next day when I fire up Anki, I still have a lot of cards due. That’s alright, because I knew I had a few days before the daily load started it’s decrease. It’s still about two weeks before the magic leveling off of 25 cards. I did have a few lapsed reviews during the session, which probably explains it.
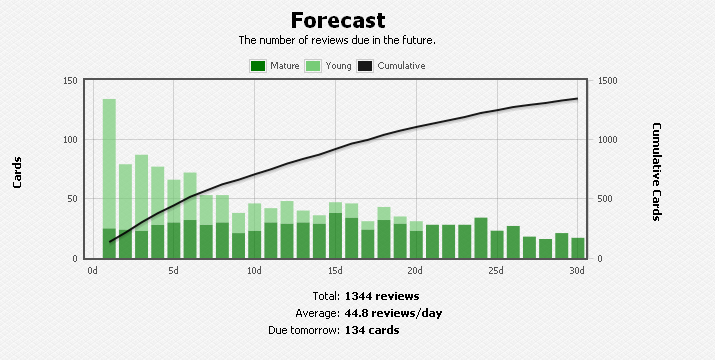
A week later, I’m still waiting for the promise of a smaller daily schedule. The graph below is my forecast a week after the first graph. Not only does the forecast look no better than it did a week earlier, but the number of cards due tomorrow is 35% more than it was a week ago!
Anki forecast at day 112
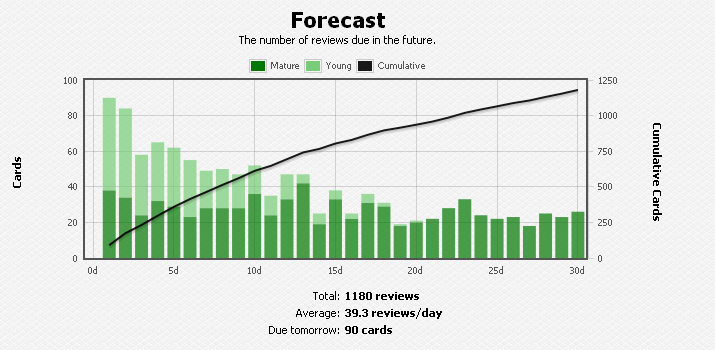
After two more weeks, I’m looking forward to the green pasture of 25 reviews a day. But wait, what’s this? What the…??
Anki forecast graph at day 126
So after three weeks of studying daily, my daily queue has gone down from 99 cards, to … 90! What is going on with the forecast graph, and why is it so far from reality?
When the Forecast Isn’t a Forecast
Actually, the forecast graph is doing just what it was programmed to do. When it claims that I will have 99 cards to study tomorrow, it is entirely correct. Where it starts to go off the rails is in all the days after tomorrow. The counts for those days do not account for the cards I will study tommorow which will end up as lapsed. Cards that lapse tomorrow will be rescheduled on day 2, increasing the actual number of reviews from what the graph shows. It also doesn’t account for all the successful reviews tomorrow, which will all be rescheduled sometime further in the future, with some of them being within the 30-day window of the graph. All of these rescheduled cards will add to the original forecast in those future days.
In other words, the forecast graph isn’t really meant to be a “forecast” of the number of cards you are likely to study. The graph is really just showing the number of cards due on each day in the future, as of this date. In fact, the source code for the graph uses terms like Due, IsDue, etc., for it’s functions, never referring to it as a forecast. A real forecast would be much more complex, and would need to run projections on probable number of successful and failed cards for each day in the future to adjust the daily counts. That would be a pretty cool feature, but isn’t what the software currently does.
An SRS-yphean Task
What about my experience of doing daily reviews, yet not making clear progress in lower my daily queue? Can this all be from a small number failed reviews?
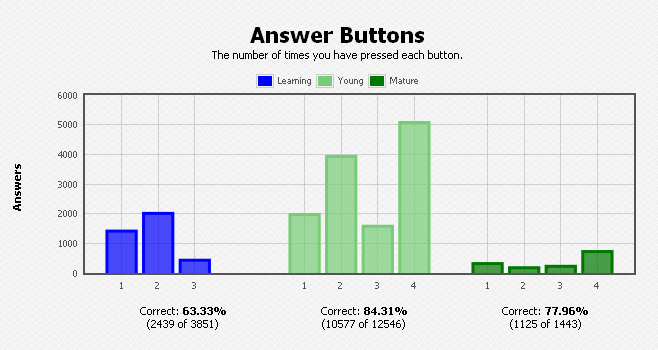
Anki has a graph that directly shows the propabilities for success and failure for a particular deck, or for all decks. This is the “Answer Buttons” graph (“The number of times your have pressed each button”). This charts the number of times each answer button (1=Lapsed, 2=Hard, 3=Good, 4=Easy) was pressed for different types of cards. Ignoring the blue Learning section on the left (which just indicates how many items you already knew), the Young and Mature areas of the graph indicate how well you knew items as they were reviewed. The Young subchart represents items that were last reviewed 21 days ago or less, while the Mature chart on the right side represents cards that were last seen over 21 days ago. The Young subchart includes some items that are difficult to remember and are repeatedly forgotten, so the average Answer Buttons tend to look less favorable compared to the Mature subchart. Mature cards have all been seen and answered successfully many times in a row, so the Mature subchart is more representative of the overall success rate of the deck. The Anki documentation suggests that the success rate (buttons 2 through 4) should typically be around 90%.
Anki’s “Answer Buttons” Graph (for a different deck)
In fact, the SRS algorithm is constructed by default to aim for this level of performance, based on the model of memory where the chance of forgetting a fact increases over time. If you wanted a higher percent of success in your SRS sessions, you would need a more aggressive daily schedule because you would be reviewing items more frequently. If you wanted a more relaxed schedule, you would be doing less reviews but would have more lapses. The various algorithms in SuperMemo allow fine tuning of many scheduling factors based on empirical data from past reviews. Anki allows a small amount of control via the Interval Modifier deck option.
A success rate of 90% seems great. It’s enough to get an “A” grade here in American schools. But a failure of 1 item in 10, or of 10 items in 100 somehow seems worse. For an SRS future schedule, it’s a significant amount. Here is the effect it has for a hypothetical deck. Say that I have a schedule of reviews as follows:
Day
Number of cards due
0 (today)
100
1 (tomorrow)
90
2
80
3
70
4
60
I have 100 cards due today. After my review session, I have successfully remembered 90 of them but forgot 10. These forgotten cards are repeatedly shown until I remember them, at which point they will be rescheduled for tomorrow. Before my review session today, there were 90 cards due tomorrow. After my session, there are now 90+10 or 100!
The next day, the situations looks slightly better. While I still have 100 cards to review, there are only 80 cards the following day instead of 90. I am likely to have around 10 lapses again (note that, except for yesterday’s lapses, these are all a different set of items than yesterday, so the chance of forgetting is the same). Thus, on day 2 I will have 90 reviews instead of just 80. In addition to the lapses, the 10 cards that were lapsed on day 0 and successful on day 1 will be rescheduled for day 2, 4, or 5, depending on how easy I marked the card.
Which has a greater influence on increasing the future queue — lapses or rescheduling? The answer wasn’t immediately obvious to me, so I set up a simulation, using the Anki simulation in Python discussesd in a previous post. I set up an initial deck to match the cards and review history in my actual deck. The particular deck has a lapse rate of about 15% (more precisely, 14.7%). Once loaded, I let the simulation run through a number of days of reviews, recording lapses and reschedules for cards that were reviewed from the first day (day 0) of the simulation forward. The answer is immediately clear:
Contribution of various factors to Anki’s review queue
The graph above conveniently combines two different but important data sets: the forecast as of day 0 of the simulation and the actual reviews on each day. The bottom area in blue is the number of cards due on future days as of day 0. Thus, it is equivalent to the forecast graph in Anki. You can see that the number of reviews quickly drops, reaching 20 reviews or below as of day 26. The combined area of all three data sets represents the number of items that were actually reviewed on each day. It is the combination of the original forecast plus any items reviewed from day 0 through day N-1 that were rescheduled. The items that were successfully reviewed and rescheduled again during the 30 day window is a minor contribution. The major contributor to the daily queue is clearly from lapsed cards. It’s such a major factor that as of day 25, the majority of reviews are coming from items that had lapsed in the previous 24 days. It’s like slow, rolling wave of forgetting.
What does it look like with a success rate better than 85% — say 90, 95, or even 100%? It’s hard to do a direct comparison because other factors come into play. While a lower rate of lapses obviously will lower the number of rescheduled reviews with all other factors being equal, a deck with fewer lapses will already have fewer scheduled cards on any given day. The graph below simulates forecast atarting from day 105, in a deck made by the addition of 20 cards a day for 100 days, followed by another 5 days of reviews with no further additions. In a deck with a 15% lapse rate, the number of cards due tomorrow is around 140, which in a deck with a 0% lapse rate, there are 80 cards due tomorrow. Two interesting observations are that the forecasts in both decks level off to 25 cards a day after about 3 weeks, and that the forecasts for both are equal after about 8 days. The dramatic difference is that the high-lapse case promises a quick drop in the number of reviews to reach that point. As we now know, that promise is not fulfilled.
The forecast for two simulated Anki decks with varying lapse rates
The Conclusion
If the prospect of a small number of reviews in the near future keeps you motivated to keep up with your flashcard study, don’t let this analysis discourage you! But if you find yourself repeatedly surprised by how your daily reviews are higher than Anki’s rosy forecast, know that you’re not doing anything wrong. Just keep plugging away. Your daily reviews will slowly but steady decrease over time, just not nearly as quickly as Anki’s forecast would have you believe.
I am a faithful user of flashcards to study Chinese words, with Anki as my software of choice to take care of the spaced repetition rescheduling. Even though I try to keep my queue empty on a daily basis, there are still days when I feel like I’m swimming against the tide. If I look at my forecast of upcoming cards, the level of daily cards quickly drops to a low baseline after a week or so. Yet, I never seem to reach the level that Anki’s forecast graph promises me. Then there are other days where I get weary of the constant drilling and skip a few days. When I come back to study, I have a large queue of overdue cards waiting for me (as expected). However, once those cards are cleared, Anki’s forecast of future cards is surprisingly good—maybe better than if I hadn’t skipped those days. Am I being punished for my diligence? Is this just my perception of the flashcard experience, or am I encountering something tangible related to SRS scheduling?
A way to test various theories was to create a simulation of Anki’s SRS scheduling.
Recently, I created a set of flashcards of single Chinese characters, to practice writing. The front of my Anki cards contained the pinyin, definition, and clozes for the most common words containing the character, while the back of the card was simply the character. I tagged the cards in groups of 200 by frequency rank, using tags of “1-200”, “201-400”, etc. I already know a number of characters, so I decided to start practicing with the more infrequent characters, the “1601-1800” tag.
There were some characters I was well familiar with. Other characters took more time to remember how to write, but weren’t too difficult, as I knew the characters on sight from extensive reading. But every once in a while I would be shown a card, and it would be for a character I had never seen before in 6 years! Some like 贼 (zéi, thief) or 鹏 (péng a mythical bird) were surprising to see in the 1600-1800 range for frequency ranks, ranked more frequent in the Lancaster Corpus than 垂 (chuí to hang down) and 夹 (jiā to squeeze). But however unusual they were, I still recall encountering them at some point (金色飞贼 is the golden snitch in Quidditch from Harry Potter, and 鹏 was from reading on Chinese mythical animals). However, 琉 (liú glazed tile) and 鲍 (bào abalone) don’t look familiar at all, and I am fairly certain I have never seen the characters 萼 (è calyx of a plant) and 懋 (mào diligent) in over 6 years of study. Is it just a strange chance that I haven’t encountered them, is it failing memory, or are they more rare than their frequency would suggest?
In my Chinese studies, the Lancaster Corpus of Mandarin Chinese (LCMC) has been a useful source of data—word and character frequencies, collocations, phrase usage, parts of speech, etc. The corpus is freely available for non-commercial and research use. However, the native form of its data is in a set of XML files, which is not an easy format to work with. In addition, the XML data is slow to read data from, because all those XML tags and the entire data structure needs to be parsed. A much better format for the data is an SQL database. Stored in a database, many kinds queries and reports can be executed very efficiently. Depending on the software, these queries and reports can return results very quickly, much faster than in the XML format.
I have made available a Perl script and some other related tools to assist with extracting the LCMC files into a SQLite database. SQLite is a lightweight relational database management system intended for portability and ease of use. Because it functions as a standalone program (not client-server), it is easy to install and use. It’s more ubiquitous than you might think. It’s how the Firefox and Chrome browsers stores its history, cookies, and preferences. But it’s also used, for example, by the Anki program as the storage format for flashcard data, and by the Calibre e-reader program to store information on installed e-books.
The HSK is a well-known skill level test used by the PRC to assess language proficiency in Chinese. Even for those who have no interest in taking the HSK test, the lists of Chinese words associated with the test are a convenient source of material for learners to study vocabulary. I have used these word lists myself with great success; it was a quick and effective way to gain a huge amount of usable vocabulary.
In 2010, the HSK exam underwent a major reworking, changing the structure of its skill ranks, increasing emphasis on speaking and writing, and revising its vocabulary. Where the “old” pre-2010 word lists consisted of 8,000+ words across 4 levels, the “new” HSK has 5,000 words distributed into 6 levels. Below is a summary of the word counts in the old and new vocabulary lists, based on actual word lists obtained from various sources (see footnotes for details). Note that these include a small amount of double counting (less than 2%) due to words repeated at more than one level, because of either different pronunciation or meaning. Also note that these counts differ slightly from the official word counts reported by Hanban.
Word counts in the old and new HSK word lists
Level
old HSK
new HSK
1
1007
153
2
2001
150
3
2189
300
4
3587
600
5
–
1300
6
–
2513
Total
8784
5016
Since I had invested so much time in studying the old lists (up to level 3), it was natural to wonder whether I should continue studying my existing flashcards or switch to the new HSK lists. How many words have I learned that are deprecated by the HSK, and does it mean they are unimportant? If I did switch, what level should I pick to start studying ?
When one searches on Google’s search page, the Chinese words and phrases can strung together without separation, just as in normal writing. What isn’t immediately obvious is that it looks like behind the scenes Google has taken the Chinese pages it crawls and segments the texts into individual words before storing the terms in its database. For example, in Google’s search of web pages, the term 中国 reports over 1 billion hits. With the same term in quotes to indicate an exact phrase, “中国” reports 5 billion hits (with the discrepancy hard to explain). However, when a space is inserted into the word, the exact phrase “中 国” reports 4.3 million pages, which is 0.08% of the amount for the single word “中国”. The kinds of pages returned from the space-separated query include matches for: 中國 in traditional script (for unknown reasons); words separated by punctuation, especially “中(国)” and “中。国” (i.e., one sentence ends with 中 and the next sentence starts with 国); and pages where every character is separated, as if the page were encoded or decoded incorrectly. These results suggest that Google treats Chinese searches the same as other languages, by storing pages in its back end database indexed by the individual words in the page. Storing the terms this way allows Google to quickly return results for a variety of queries, whether the user wants the terms anywhere in the page or as a connected phrase.
With reading as my primary skill of focus in learning Chinese, a large part of my study is acquiring new words. Some vocabulary is from general word lists such as the HSK, while much of it is tied to a specific text I am reading, in order to increase my level of comprehension. While many approach the task of reading in a foreign language by looking up unknown words as they are encountered, I prefer to learn them ahead of time, to avoid the break in concentration while reading. With my bad habit of perfectionism, my main strategy in the past for learning these word has been the “Brick Wall Method”:
The Brick Wall Method – Learn every unknown word you encounter, no matter how difficult or rare it is
My theory has been — like being a brick wall against a tennis player — to not let any unknown word get past me, so that eventually I will run out of unknown words and thus will have learned the language. If a word is used in a text, it’s clearly important to some nominal degree, and if it’s used once, then it’s more likely to be seen again at some point, versus all the words that aren’t in the text.
I have had my online vocabulary extraction tool available on the web for a while now. I have gotten a lot of use out of it myself, as my primary interest has been to develop more vocabulary to increase reading ability. The application generally works ok, but it suffers from some technical issues. Because it loads the entire CC-CEDICT every time it runs, it taxes the shared hosting provider a lot, to the point where the script crashes unpredictably, especially for larger texts. It also requires manual intervention to keep the dictionary up to date, and adding more dictionaries takes a lot of additional effort.
Meanwhile, for the past year I’ve been working on a similar program that can be used offline. It has been working well, is a little faster, and is easier to drop in newer versions of the CC-CEDICT dictionary. I have spent a few months adding a little more polish to it, and now am releasing it as open source software. At this point, it is available for Windows systems. The source code is also available, which would allow it to be used on nearly any system. More details are at the project page and the documentation page. Here are some screenshots to demonstrate its functionality: